



We at Zapr Media Labs collect TV viewership information from millions of smartphone users and analyze what they watch on television. Our technology helps us find answers to questions like what content is trending on television, and ultimately helps us understand the interests and preferences of the user.
Zapr’s core algorithm matches fingerprints from mobile with channels on our servers to generate actual viewership data. Based on our algorithm, we find the best potential channel for the given sample of a user. The problem with the repeating best possible match is that we just get one potential candidate, which we accept or reject based on our cutoff criterion. Whereas, in reality, it is possible that there are multiple TV-channels that can match for a user. This is what we call the ‘Multi-Audio-Detection problem’.
When would multi channel match happen and why does it bother us?
Many a time it happens that the same content is being aired across multiple channels e.g. live telecast of certain events like sports (Cricket or Football), political events (Independence day speech by the Prime minister) or cultural activities (Republic day parade) by multiple channels. More commonly channels with an HD counterpart will have similar content most of the time.
For channels with large viewership trends, these miss-attributions do not affect much in an aggregated report. However, for channels with relatively small viewership e.g. the HD channels, these causes sudden spikes which is undesirable and send wrong information to clients performing competitive studies. Moreover, these wrong records affects the metric called ‘Total durations watched’. Since we sample for data every 5 minutes, if we see a user is viewing the same channel in two consecutive samples we pre ‘Total durations watched’ to be 10 minutes. Therefore, there will be a huge gap between ‘Total durations watched’ for a channel if we do not correct the individual records. With the difference between HD/SD content airing lag reducing over time, the mismatch in numbers are glaring.
We have a strong need to build a simple yet effective solution.
Conceptualization Challenges
If you have paid attention till now, you would wonder how do we even evaluate the effectiveness of any algorithm we develop. There is absolutely no way we can generate any gold-standard data to compare with. We might as well randomly attribute some arbitrary channel to a user based on the first match, or maybe just use an heuristic to ensure the percentages our clients look for remains believable.
The answer lies in commercials. We bet on the fact that the commercials that get aired in each channel is different. Therefore, for a long running show there will certainly be a time when the commercials will point us to the correct match among the good records. We have done numerous empirical studies to ensure this is the case for most of the record, for those where nothing can help us, we break tie randomly.
We have observed that we can correctly resolve X% of records with certainty.
Multi-Audio-Channel-Correction
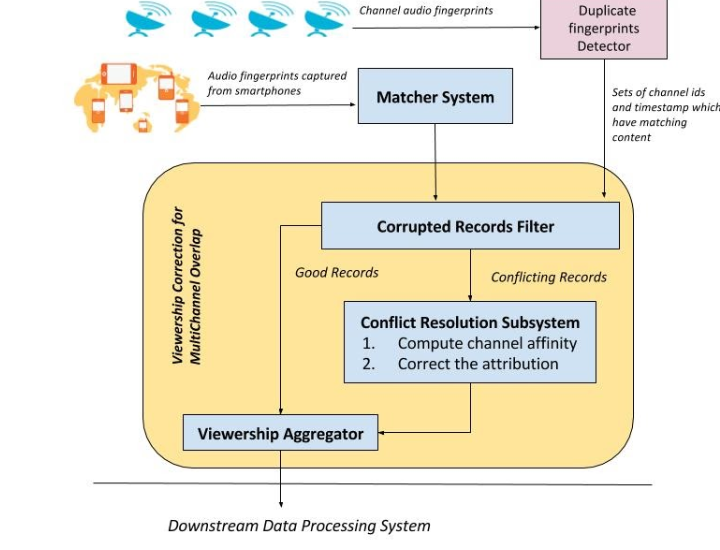
Once the viewership data for a day has been generated, we process it to determine the correct channel for the users during all those time slots when the audio content is similar for multiple channels. As it sounds, this is a batch processing job which looks into a day’s worth of data for every user and performs the correction if required.
The algorithm works with two major input:
- First it identifies the group of TV channels which match with each other in terms of audio at the same time in real time.
- Secondly, it leverages the user’s viewership trend on the same day to determine the potentially correct channel when there is a problem of multi-audio duplication. User’s affinity for certain channels over others helps us to find the best possible match.
Correction principals:
We find out the best possible channel that the user might have watched when multi-audio-content is detected in two phases:Weighted Temporal Selection: This approach gives more weightage to the channels which lie close to the region where there is multi-channel overlap. Suppose the content overlap problem occurs at the Tth time interval during the day. It is very likely that the channel watched by the user during Tth-x minute was also being watched by the user during the time when problem occurred.
Weighted Temporal Selection: This approach gives more weightage to the channels which lie close to the region where there is multi-channel overlap. Suppose the content overlap problem occurs at the Tth time interval during the day. It is very likely that the channel watched by the user during Tth-x minute was also being watched by the user during the time when problem occurred.
1) Find the user’s affinity towards each overlapping channel by determining the number of times the user has watched each conflicting channel per hour.
2) Weightage of each overlapping channel is decided based on two factors: a) channel frequency of a user per hour and the time difference between the overlapping channels and b) the user’s conflicting channel. Therefore, the closer the overlapping channel’s time is to the user’s conflicting channel time, the higher is its weightage.
3) Weightage of each channel is calculated by summing up the weighted channel frequency per hour which is determined by multiplying the channel frequency of a user per hour with the exponential decaying factor on the time difference.
Here is the formula:

4) The channel with maximum weightage is selected as the candidate for replacement.
Channel Selection On Uniform Hashing: This approach tries to find out the replacement channel based on the overall viewership trend of a user for the day. Hashing is done based on the user-id and timestamp. Hashing is used to make the multi-channel-correction job idempotent so that the user is marked with the same replacement channel each time the job runs.
i) Weights are assigned to all the channels which the user has watched during the day.
ii) Each channel is assigned weightage depending on the amount of time the user has spent on a channel.
iii) Channels are sorted based on their weighted channel frequency.
iv) Murmur Hash is used to select the replacement channel.
MACC Detailed algorithm:
Mark Duplicate: The first step is to identify the channel sets that are playing similar audio content at the same time over the day in question.
We perform the next steps for every user Ui:
- Marking for correction: Find the time slots for every user where there is a problem of overlapping channel content and isolate them by marking them as conflicting and rest as non-conflicting.
- Compute affinity: We compute the frequency of every channel watched in the non-conflicting portion of viewership.
- Correction: For every conflicting time
- We first use the weighted temporal selection approach to find the replacement channel using the formula (1)
- If the user has not watched any of the channels which lie in the overlapping region, we use channel selection on uniform hashing approach to find the correction channel.
- All the conflicting records are marked as “content overlap records” and for such records we keep the original conflicting channel and the replaced corrected channel.
Implementation Challenges
The algorithm looks simple, however, the primary challenge was to scale this to work on large amount of data. In one hand, we need to identify similar channel content which required us to cross validate all the audio fingerprints generated by each and every channel throughout the day. On the other hand we want to process 100 Million users records individually for marking, computing affinity and correction. We decided to perform the correction in a batch processing manner at the end of the day. We have written multiple Spark jobs to do the deed. The jobs are scheduled for a daily run through an Oozie workflow, which runs on our Data Lake platform.
Moving Forward
We are always evaluating and improving the algorithms we build at ZAPR. We certainly see some obvious scope of improvements.
- We want to move to a near-real time system where we can make decisions based on the immediate history of good records generated for a user.
- We want to consider additional inputs about an individual user learning from their historical viewing trends, for better resolution of ties between candidate channels.
This is a glimpse of one of the extremely interesting problems we are solving at ZAPR. Rest assured, there are plenty of interesting and rewarding challenges ahead. We are just getting started!
