


At Zapr, we have the world's largest repository of offline media consumption and we bridge the gap between offline and online worlds by enabling TV-to-Mobile audience engagement.
There are a lot of teams like Data insights, Engineering, AdOps, etc at Zapr that need to access the data on a daily basis. We have our own in-house data lake to serve this purpose.
Click here to learn more about the ZAPR data lake architecture (https://blog.zapr.in/zapr-data-lake)
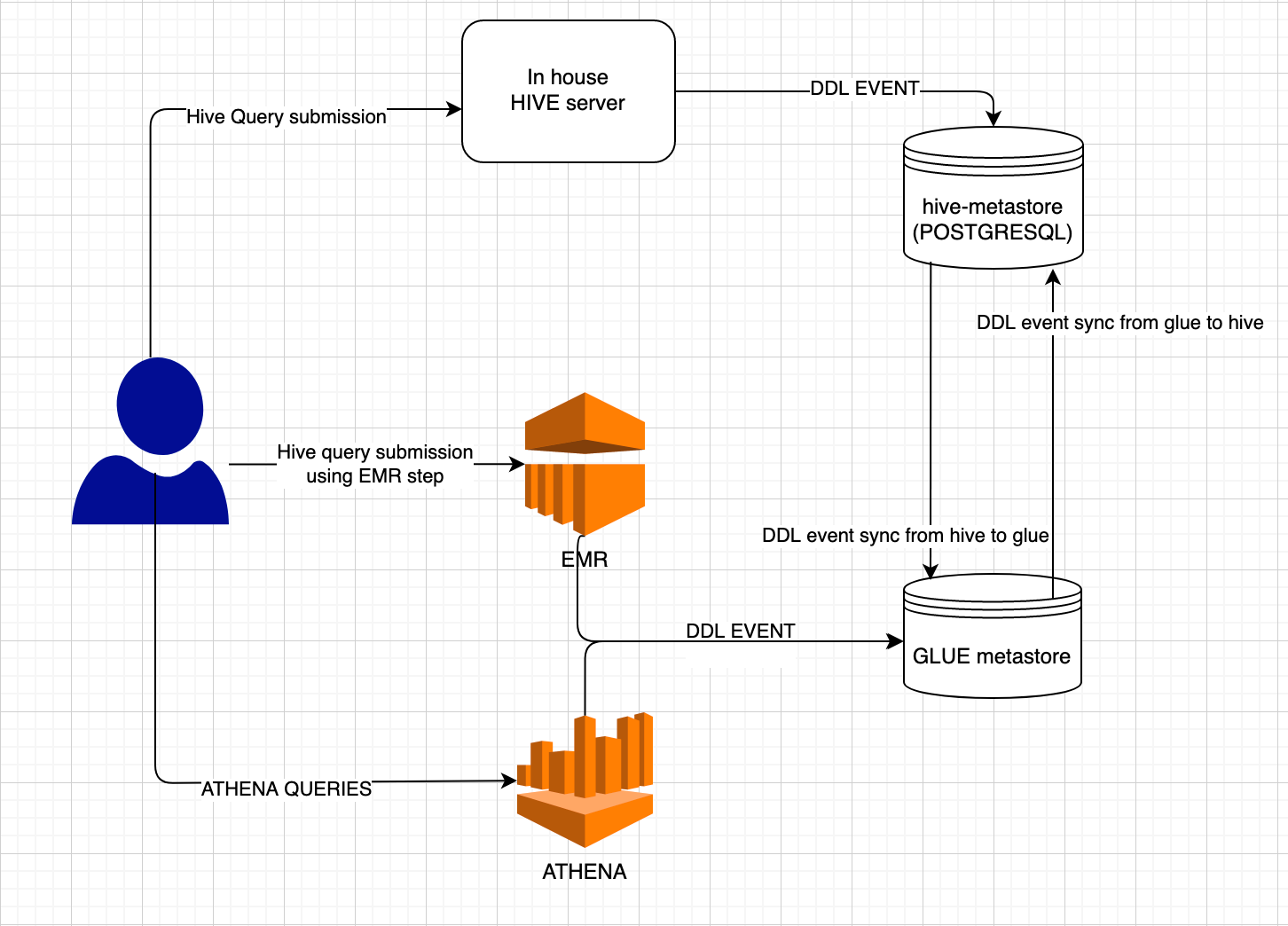
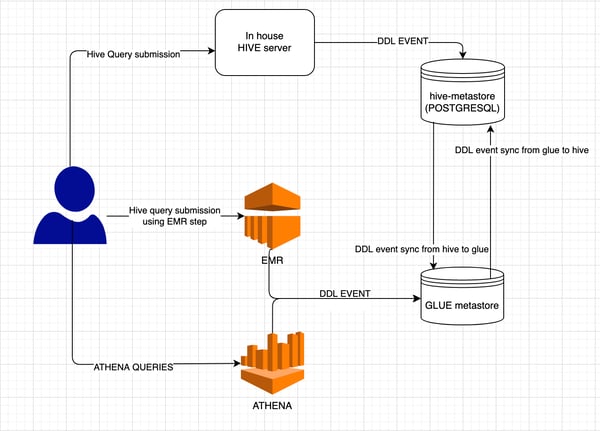
Two Metastores
The Hive service of our cluster had its own metastore which was backed by PostgreSQL and we were using a lake cluster to run ETL, client reports generation and many such jobs. Later, we started using EMR for some of our workloads, to achieve isolation and meet the SLAs. In EMR, at that time, there was no feature of providing external hive metastore. So, we had to use AWS glue as a metastore in EMR.
Since we were running some of the workflows in the in-house lake cluster and some of the workflows in EMR, we were keeping two metastores in the organization with the same meta-data. We had to make sure that both metastores were in a consistent state. We were using our cluster’s hive to run any query or ETL job. So, our requirement was to make sure that any DDL event that happened using EMR, must be reflected over the hive metastore and vice versa.
Hence, what we used to do was, in the EMR step, we submitted a workflow in our in-house cluster, which added DDL changes of glue to hive metastore. So, there was one more overhead on the developer to make sure that they made DDL changes on both metastores.
This way, we had solved the problem of reflecting changes from glue to hive metastore. Now, to reflect changes of hive metastore to glue, we had deployed a hive-glue-sync agent. The hive-glue-sync-agent was consuming DDL events using the hive metastore-event-listener hook and reflecting DDL events from hive metastore to glue. Thus, until now, our use cases were solved to some extent. But after a while, we started using AWS athena for all data analytical purposes and reports generation. AWS athena did not support (in ap-southeast-1 region) external hive metastore to keep the metadata of the tables. So, we had to use AWS glue as a metastore here too. Now, we had to consume DDL events from an athena query and add them in hive metastore which caused the problem of cyclic dependency.
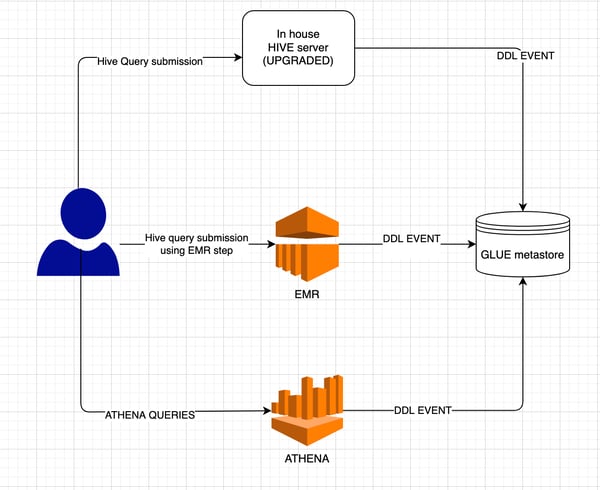
We had to solve this problem. As we found out, glue can be supported in Vanilla hive 1.2 and 2.3 versions. But our cluster’s hive version was 1.1. So, we had to upgrade the hive version. We deployed hive 2.3.5 with glue as a metastore which solved the problem of cyclic dependency of metastore.
“Now developers need not worry about the two metastores and there was no need to add an additional step to keep the metastores consistent”
Reducing the query execution time
Hive is a better option if we want to run ETL jobs on bigger data but not a good choice if someone wants to perform interactive data analysis using query. Our Data Insights team and the developers struggled with our in-house hive cluster which had limitations on the scaling.
As we have a small team, Athena is a better option for us. Athena is faster and more reliable because it is a managed service provided by AWS. Hence, we don’t need to worry about maintenance. We only have to pay for the data we query. So, we moved many of our ETL jobs and Data Analysts to Athena. We are using upgraded hive cluster to query internal custom formatted data which is not supported in Athena. The usage of the updated hive cluster is minimal now. We are using zapr-oss/zapr-athena-client to submit the query and create ETL jobs.
Cost and Maintenance
The CDH lake setup was done over AWS cloud using the bare VMs (EC2) mostly spot type. The CDH version used was 5.12.
Brief of topology:
-
There was a CDH manager running on one on-demand type ec2 instance.
-
HDFS cluster with 1 Namenode and 5 Datanodes running on on-demand ec2 instance.
-
Yarn cluster with 2 Resource managers running on on-demand instance and a spot fleet of Node managers.
-
Oozie setup on 1 on-demand instance.
-
HUE UI on 1 on-demand instance.
-
Hive Server and Hive metastore on 1 on-demand instance
Operational challenges:
-
Managing HDFS required significant effort. Scaling up and down too frequently was not an option with HDFS, hence we always needed to over-provision. Any new workload churning large volumes of data required manual scaling of the HDFS cluster. Identification of this scale-up could not be pre-identified. Any person querying some large data in text format may bloat up the HDFS usage.
-
At times, HDFS went into safe mode due to any heavy AdHoc workload, which later required manual intervention.
-
There was no complete isolation of services and resources in this setup, which tends to create a ripple effect on other running workloads. We had leveraged yarn queues along with user level access control via combination of LDAP and sentry. But these did not provide true isolation nor did they provide very granular role-based access control. Hence, managing this for all team members wasn’t easy.
-
Scale-up and scale-down of node managers were not very stable and consistent. There were a couple of moving parts which were used to achieve this: python scripts to identify the needs of scale up/down, scripts to add/remove nodes from the cluster, provisioning of nodes on cloud, signaling of availability of node to the scripts so that they can add them in the cluster. Any issue or abnormal behavior in any of these parts required manual effort.
-
Identification of the right size of container for processing in the YARN cluster was very difficult where the same cluster was used for a multi type processing framework like spark, hive, hadoop-mr, java, etc. Any major variation in workload type required a manual identification of right size for containers.
-
Managing of intermediate disk usage in shuffling, sorting and spilling. Any AdHoc processing could spike up this usage which had to be handled manually.
-
A lot of times, node manager became a bottleneck, for which the only option was to either kill some jobs and resume them later or kill all the jobs and upscale the node manager container.
“As we migrated all of our ETL jobs to Athena, we are now able to increase productivity and significantly reduce cloud costs”
Gaurang Patel
Software Engineer [Platform - Engineering]
ZAPR Media Labs

