We love our Data
Life of a software engineer at Zapr revolves around taking care of the data we bring in: trimming down the unnecessary weight, polishing it in a way that brings the best out of the data, and then finding a place for it to stay with us forever. Everyone owns some part of the data; the journey of sharing and caring for it here at ZAPR. As the core-platform team, our responsibility is to help out everyone by providing the platform and tools for seamless data experience. And there comes our biggest product, the Data Lake.
Pain areas we wanted to address
At Zapr, we query data for multiple reasons:
- Reporting every day operational data
- Generate viewership data for long term clients according to their requirements
- Generate viewership data for short term clients which are more ad-hoc in nature
- Generate target user base to initiate an ad-campaign
- In-house data analysis and insights discovery
- Generating ad-hoc reports for Sales, Marketing, Operations and Strategy Team.
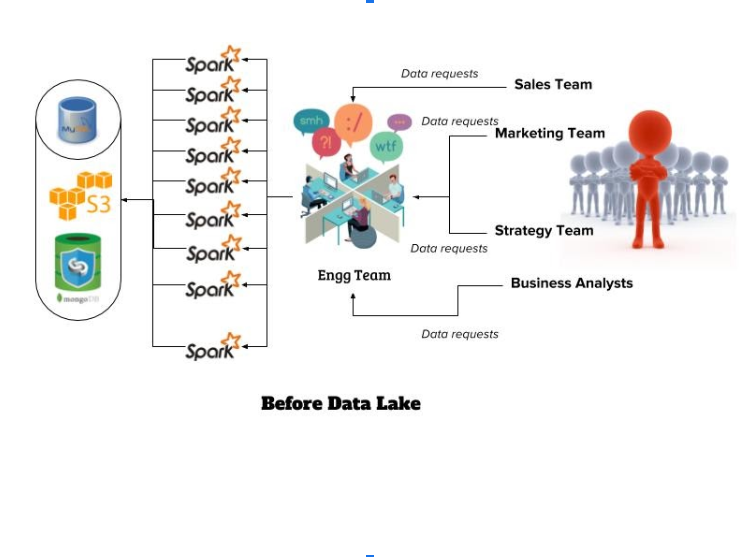
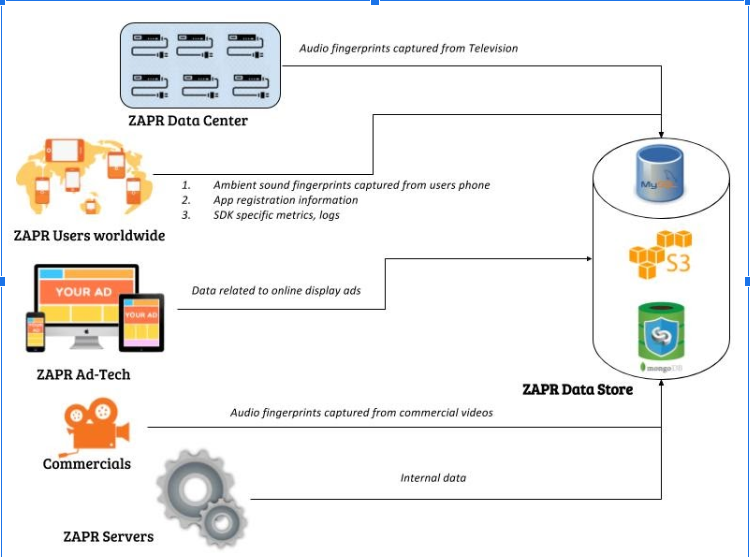
We already had a defined and well maintained data processing pipeline to cater to the first three needs. However, due to the unpredictability in the next three cases we resort to ad-hoc reporting with help of developers at Zapr. The data was stored partly in S3, partially in HDFS and rest in MySQL or MongoDB. Our Sales, Marketing teams and mostly Data Analysts are continuously envisioning new and innovative ways (means more complex) to enrich and sculpting the existing data for operational reporting and advanced analytics. With the evolution of their needs coupled with lack of holistic knowledge about the data or the intent behind the reporting, it always ended up being a long and arduous exercise for the developers to assist them. This was neither a good use of of their time nor expertise. The obvious flaws diagnosed were:
- Timeliness. Introducing new content to the existing data pipeline and communicating the same to stakeholders were a cumbersome process. When we needed immediate access to data, even short processing delays can be frustrating and led us to bypass the proper processes in favor of getting the data quickly themselves. There were no time guarantees provided.
- Flexibility. We not only lacked on-demand access to any data we may need at any time, but also the ability to use the tools of our choice Every data retrieval process was a separate spark job. Additionally, we wanted to join and aggregate data across many different formats, which led to even more chaos and complex codes.
- Quality. Nobody would trust the data if the origin and the action upon it is unclear.. Also, if we worry that there is missing or inaccurate data, we might get forced to circumvent the core data in favor of getting the data ourselves directly from other internal or external sources, potentially leading to multiple, conflicting instances of the same data. An interesting aftermath was that our AWS S3 stores were flooded with tons of intermediate data.
- Diagnostics. Looking into the data for root cause analysis was difficult and time consuming. In a single data pipeline every team working on it would keep their own sanity checks which were not known to others up or down the stream.
- Discoverability. Sales, Marketing and Analyst teams did not have a function to rapidly and easily search and find the data they needed when they required it. Inability to find data also limits their ability to leverage and build on existing data analyses.
- Advanced analytics users require a data storage solution based on an IT “push” model (not driven by specific analytics projects). Unlike existing solutions, which are specific to one or a small family of use cases, what is needed is a storage solution that enables multiple, varied use cases across the enterprise.
This new solution needs to support multiple reporting tools in a self-serve capacity, to allow rapid ingestion of new datasets without extensive modeling, and to scale them while delivering performance. It should support advanced analytics, like machine learning and text analytics, and allow users to cleanse and process the data iteratively and track lineage of data for compliance. Users should be able to easily search and explore structured, unstructured, internal, and external data from multiple sources in one secure place.
The solution that fits all of these criterias is the Data Lake.
What is Data Lake?
Data Lake can be considered a system which provides unlimited amount of storage and compute to the developers for processing, storing as well as querying and visualizing data of any size and shape, thrown at varying speed.
A Data Lake enables users to analyze the full variety and volume of data stored in the lake. This necessitates features and functionalities to secure and curate data and run analytics, visualization, and reporting on it. The characteristics of a successful Data Lake include:
- It needs to be domain sensitive and tailored for the nature of query.
- It needs to leverage multiple tools and technologies.
- It needs to provide configurable ingestion workflows.
- It should scale elastically according to the compute and storage needed.
- It should provide access restriction for various user pools.
- It should provide an easy to use UI for both technical and non-technical users.
Keeping all of these elements in mind is critical for the design of a successful Data Lake. In the blog-series we would take a deep dive on each of the topic subsequently.
Our choices
Our servers are majorly hosted on Amazon EC2 or Spot instances. Amazon provides an EMR service which does tick off most of the use-cases in addition to painless maintenance. However after much debate and discussion we chose to maintain our own setup.
Why not EMR
Our system is to be up and running 24×7. Keeping a 24×7 EMR setup is extremely cost heavy. Therefore, the most pertinent point is about being frugal and reducing our infra costs followed by flexibility of adding new softwares along with upgrading the existing ones. EMR is known to provide the following advantages, which we have overcome by leaps and bounds;
- Auto scaling with Spots: Our custom auto scale script is 40% more efficient with respect to resource utilization than EMR since our algorithm is sensitive to our needs. The class of spot-machines we spawn as worker nodes are optimal for Lake’s real time demand.
- Dynamic Orchestration: Not required, we prefer a single setup and never intend to go over-budget. The possible data-scale issue is contained with spawning better machines inside same availability zone. Note that our requirement never is to have real-time answers to queries.
- Access to Amazon S3: Most of our data lies in S3 and with the S3 connector feature of Cloudera 5.12, we benchmarked the performance of usual SPJ (Select-Project-Join) queries where EMR leads marginally. In addition to that we have a flexibility of storing data on HDFS as well.
Cloudera is comparatively more difficult to learn and configure. But once you have it setup, it’s far more flexible than EMR, and there’s no extra infrastructure cost. Cloudera Manager has an easy- to – use web GUI. This helps manage and monitor Hadoop services, cluster, and physical host hardware. We have also successfully deployed Sentry authorization on top of LDAP to restrict users in accessing the Lake according to their respective roles, which would have not been possible with EMR.
Why Cloudera?
We need to be truthful on why we chose Cloudera and not any of the other open source platform. The answer is GUI. HUE is by far the most exquisite user interface for Hadoop users in addition to its pluggability feature. The Cloudera Manager portal provides one stop shop for adding, removing, modifying and deploying any service in a completely hassle free manner. It allowed us to create meaningful dashboards and alerts for round-the-clock monitoring for free.
Cloudera manager automatically raises conflict alerts on poorly configured setups It has built in help tips with each and every Hadoop feature and recommends better values for allocating resources. Everyday we get to learn something new just expanding the help tips (and of course researching around a bit). Every check-in is saved and one can roll back to the older set-up anytime. This way all our operational efforts boiled down to a few clicks.
Similarly HUE has been a life saving tool for providing non-technical users a query interface at ZAPR. Our analysts would create workflows, queries with parameters and share with the Operations and Sales team in a read-only manner for them to execute on-demand with their own set of parameter values. Any update on the queries and workflows can be deployed easily through HUE. We saved time and effort in building separate web-portal for them. With the Sentry setup, everyone has restricted access according to their team permission level. We were able to neatly divide team – based temporary workspaces (read database) for storing data. In the background, we periodically cleanup the temporary workspaces to minimize S3 cost as well. Note that, since we deal with huge amount of data and reporting everyday, our S3 cost did hit the roof before for lack of cleanup of temporary data storage.
We will share the following stories in these blog-series:
- Architecture of ZAPR Data Lake
- Autoscaling YARN nodes on Amazon Spot-fleet
- How to provide access restriction using LDAP and Sentry
- Semantic Search on Solr
- Learnings from setting up Cloudera’s CDH platform on AWS
Also read How Atreyee Dey redefined both Big-Data problems and Gender Norms.